Santali-language text typed in Ol chiki using ASCII and other legacy encoding systems can now be converted to Unicode so that the text can be used universally, online content will be easily searchable and users can reuse content with ease.
If you know of a language that is used by a considerably small group of people and is written by a script other than Latin or Mandarin or Russian (or any such well known ones), there might be a chance that they use a non-standard character encoding instead of Unicode, a globally accepted standard character encoding.
But why a common user should bother? Most non-standard character encoding used in the industry are modified ASCII encoding. ASCII or the American Standard Code for Information Interchange became widespread in the 1960s before the advent of Unicode. Anyone can create their own version of ASCII for their own writing system by replacing a Latin character by one of their own. So, as a result of that, a native language character would appear when one types a Latin character, say “A” or “B”. It’s a faulty system in today’s context as Unicode was primarily created to solve such multiple standards (or the lack of that) for any writing system. It provides specific values for each character of an alphabet. So, no matter, what font one uses, the characters will be displayed uniformly in all computers/other devices.
Unicode in a way unifies different fonts — the way characters look because of varied styles and aesthetic looks. In the case of Santali, many publications like the Fagun magazine have been using a non-standard and modified ASCII character encoding since long. But one cannot find their content by a simple Google search as it is not in Unicode.
I’m really excited to announce that with support from community leaders like Ramjit Tudu who supported a lot with the character mapping, we have built a converter to convert from Santali text in Latin into text in Ol chiki.
The code is released under an MIT license and is available in our GitHub repo.
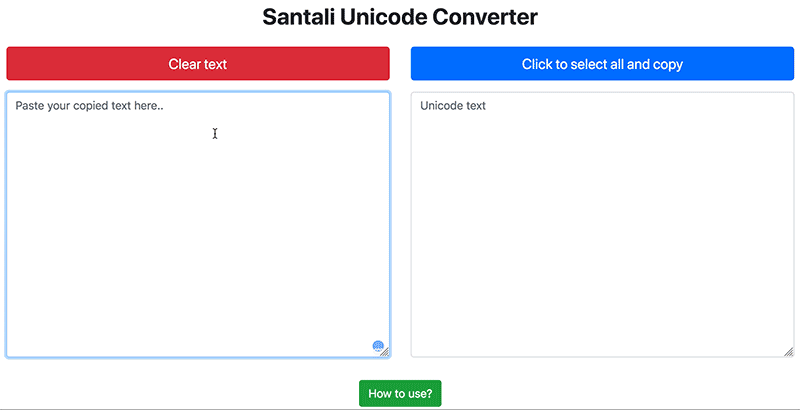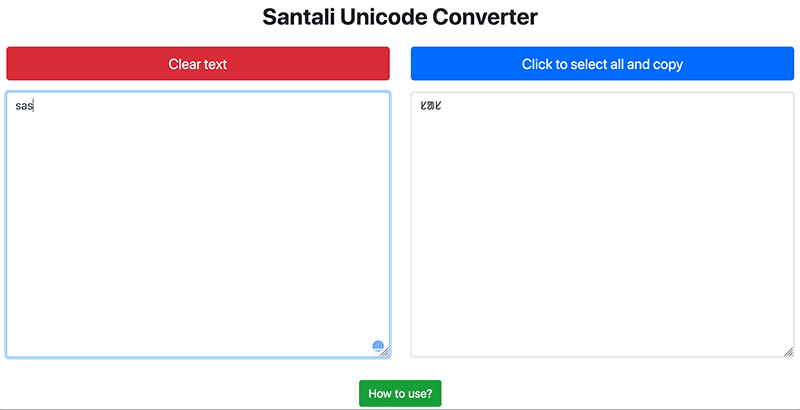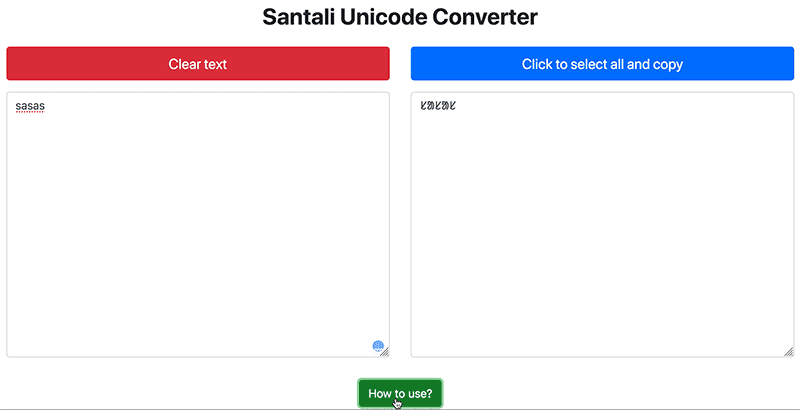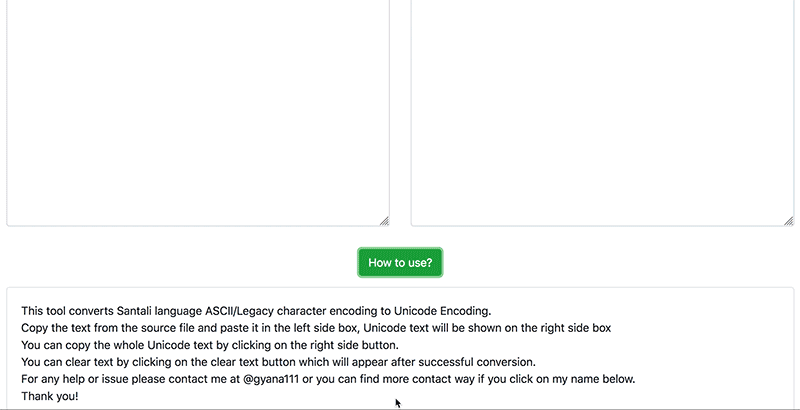
How to use the converter? See the tutorial below:
More related



How to convert santali unicode to olchiki